賈里尼克從來不是真正的計(jì)算機(jī)科學(xué)家,而他的專長是信息論和通信,因此他看待語音識別問題完全不同于人工智能的專家們--在他看來這是一個通信問題。人的大腦是一個信息源,從思考到合適的語句,再通過發(fā)音說出來,是一個編碼的過程,經(jīng)過媒介(空氣或者電話線)傳播到聽眾耳朵里,是經(jīng)過了一個長長的信道的信息傳播問題,最后聽話人把它聽懂,是一個解碼的過程。既然是一個典型的通信問題,就可以用解決通信問題的方法來解決,為此賈里尼克用兩個馬爾可夫模型分別描述信源和信道。當(dāng)然,為了訓(xùn)練和使用這兩個馬爾可夫模型,就需要使用大量的數(shù)據(jù)。采用馬爾可夫模型,IBM 將當(dāng)時的語音識別率從70%左右提高到90%以上,同時語音識別的規(guī)模從幾百詞上升到兩萬多詞 (Jelinek, 1976),這樣,語音識別就能夠從實(shí)驗(yàn)室走向?qū)嶋H應(yīng)用。 賈里尼克和他的同事在無意中開創(chuàng)了一種采用統(tǒng)計(jì)的方法解決智能問題的途徑,因?yàn)檫@種方法需要使用大量的數(shù)據(jù),因此它又被稱為是數(shù)據(jù)驅(qū)動的方法。
賈里尼克的同事彼得?布朗在1980年代,將這種數(shù)據(jù)驅(qū)動的方法用于了機(jī)器翻譯 (P.F. Brown, 1990)。由于缺乏數(shù)據(jù),最初的翻譯結(jié)果并不令人滿意,雖然一些學(xué)者認(rèn)可這種方法,但是其他學(xué)者,尤其是早期從事這項(xiàng)工作的學(xué)者認(rèn)為,解決機(jī)器翻譯這樣智能的問題,光靠基于數(shù)據(jù)的統(tǒng)計(jì)是不夠的。因此,當(dāng)時SysTran等公司依然在組織大量的人力,寫機(jī)器翻譯使用的語法規(guī)則。
如果說在1980年代還看不清楚布朗的方法和傳統(tǒng)的人工智能的方法哪一個更適合計(jì)算機(jī)解決機(jī)器智能問題的話,那么在1990年代以后,數(shù)據(jù)的優(yōu)勢就凸顯出來了。從1990年代中期之后的10年里,語音識別的錯誤率減少了一半,而機(jī)器翻譯的準(zhǔn)確性提高了一倍,其中20%左右的貢獻(xiàn)來自于方法的改進(jìn),而80%則來自于數(shù)據(jù)量的提升。當(dāng)然,這背后的一個原因是,由于互聯(lián)網(wǎng)的普及,可使用的數(shù)據(jù)量呈指數(shù)增長。
最能夠說明數(shù)據(jù)對解決機(jī)器翻譯等智能問題的幫助的,是2005年NIST對全世界各家機(jī)器翻譯系統(tǒng)評測的結(jié)果。
這一年,之前沒有做過機(jī)器翻譯的Google,不僅一舉奪得了各項(xiàng)評比的第一名,而且將其它單位的系統(tǒng)遠(yuǎn)遠(yuǎn)拋在了后面。比如在阿拉伯語到英語翻譯的封閉集測試中,Google系統(tǒng)的BLEU評分為51.31%,領(lǐng)先第二名將近 5%,而提高這五個百分點(diǎn)在過去需要研究7—10年;在開放集的測試中,Google51.37%的得分比第二名領(lǐng)先了17%,可以說整整領(lǐng)先了一代人的水平。當(dāng)然,大家能想到的原因是它請到了世界著名的機(jī)器翻譯專家弗朗茲·奧科(Franz Och),但是參加評測的南加州大學(xué)系統(tǒng)和德國亞琛工學(xué)院系統(tǒng)也是奧科寫的姊妹系統(tǒng)。從奧科在Google開始工作到提交評比結(jié)果,中間其實(shí)只有半年多的時間,奧科在方法上沒有做任何改進(jìn)。Google系統(tǒng)和之前的兩個系統(tǒng)唯一的不同之處在于,前者使用了后者近萬倍的數(shù)據(jù)量。
下表是2005年NIST評比的結(jié)果。值得一提的是,SysTran公司的系統(tǒng)是唯一采用傳統(tǒng)的語法規(guī)則進(jìn)行機(jī)器翻譯的。它和那些采用數(shù)據(jù)驅(qū)動的系統(tǒng)相比,差距之大已經(jīng)不在一個時代了。
從阿拉伯語到英語的翻譯 (封閉集)
Google 51.31%
南加州大學(xué) 46.57%
IBM沃森實(shí)驗(yàn)室 46.46%
馬里蘭大學(xué) 44.97%
約翰?霍普金斯大學(xué) 43.48%
……
SYSTRAN公司 10.79%
從中文到英語翻譯 (開放集)
Google 51.37%
SAKHR公司 34.03%
美軍ARL研究所 22.57%
表1 2005年NIST對全世界多種機(jī)器翻譯系統(tǒng)進(jìn)行評比的結(jié)果
到了2000年之后,雖然還有一些舊式的學(xué)者死守著傳統(tǒng)人工智能的方法不放,但是無論是學(xué)術(shù)界還是工業(yè)界,機(jī)器智能的主流方法是基于統(tǒng)計(jì)或者說數(shù)據(jù)驅(qū)動的方法。與此同時,另外兩個相關(guān)的研究領(lǐng)域,機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘也開始熱門起來。
2012-2014年,筆者曾經(jīng)負(fù)責(zé)Google的機(jī)器問答項(xiàng)目,并且通過使用大數(shù)據(jù),解決了30%左右的問題,這遠(yuǎn)遠(yuǎn)超過了學(xué)術(shù)界迄今為止同類研究的水平。究其原因,除了Google在自然語言處理等基礎(chǔ)算法上做到了世界領(lǐng)先之外,更重要的是,Google將這個過去認(rèn)為是存粹自然語言理解的問題變成了一個大數(shù)據(jù)的問題。首先,Google發(fā)現(xiàn)對于用戶在互聯(lián)網(wǎng)上問的各種復(fù)雜問題,有70-80%左右的問題可以在前十條自然搜索結(jié)果(去掉廣告、圖片和視頻等結(jié)果)中找到答案,而只有20%左右的復(fù)雜問題,答案存在于搜索結(jié)果的摘要里。因此,Google將機(jī)器自動問答這樣一個難題轉(zhuǎn)換成了在大數(shù)據(jù)中尋找答案的摘要問題。當(dāng)然,這里面有三個前提,首先答案需要存在,這就是我們前面講到的大數(shù)據(jù)的完備性;其次,計(jì)算能力需要足夠,Google回答這樣一個問題的時間小于10毫秒,但是需要上萬臺服務(wù)器同時工作;最后,就是要用到非常多的自然語言處理算法,包括對全部的搜索內(nèi)容要進(jìn)行語法分析和語義分析,要能夠從文字的片段合成符合語法而且讀起來通順的自然語言等等。其中第一個前提是只有Google等少數(shù)大公司具備,而學(xué)術(shù)界不具備,因此這就決定了是Google而非學(xué)術(shù)界最早解決圖靈留下的這個難題。
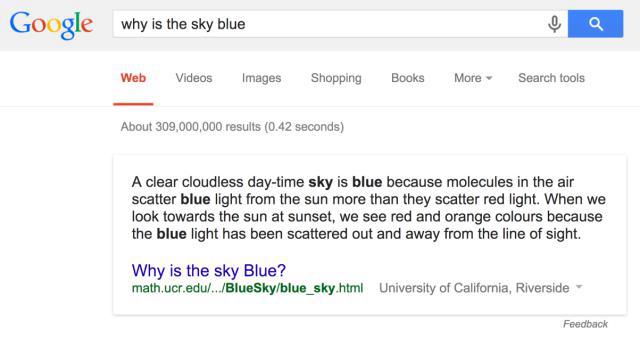
圖 3 Google自動問答(問題為“天為什么是藍(lán)色的?”,問題下面是計(jì)算機(jī)產(chǎn)生的答案)
由此可見,我們對數(shù)據(jù)重要性的認(rèn)識不應(yīng)該停留在統(tǒng)計(jì)、改進(jìn)產(chǎn)品和銷售,或者提供決策的支持上,而應(yīng)該看到它(和摩爾定律、數(shù)學(xué)模型一起)導(dǎo)致了機(jī)器智能的產(chǎn)生。而機(jī)器一旦產(chǎn)生了和人類類似的智能,就將對人類社會產(chǎn)生重大的影響了。
轉(zhuǎn)載請注明:北緯40° » 大數(shù)據(jù)、機(jī)器智能和未來社會的圖景

斗機(jī)時代已經(jīng)過去.jpg&h=110&w=185&q=90&zc=1&ct=1)

械姬.jpg&h=110&w=185&q=90&zc=1&ct=1)